Building Streaming Data Delivery Pipeline on AWS using Amazon Kinesis solution


👉🏻 This walkthrough is to stimulate a real world use case of building a streaming data pipeline for an e-Commerce platform. With Amazon EC2 generated clickstream data, we will be building a solution using Amazon Kinesis Data Firehose delivery stream for data delivery.
Streaming data is data that is generated continuously by thousands of data sources, such as log files generated by customers using your mobile or web applications, ecommerce purchases, in-game player activity, information from social networks, etc.. [1]
By processing streaming data, companies are able to perform prompt actions based on real-time activities, apply machine learning algorithms for events recommendation, or extract deeper insights from the data.
In the following use case, we will be stimulating an example for an online shopping platform and using various AWS resources to build streaming data solutions.
1. Use Case Scenario: XCorp. e-commerce platform
Xcorp is an online shopping platform that sells consumer goods such as books, food, apparel, electronics and home products. Xcop wants to analyze the clickstream data from e-commerce store for future analysis.
As the data engineering teamof Xcorp, we are targeting to build a solution on AWS to collect and deliver the clickstream data for downstream processing and analysis. We aim to find the solution that can:
be fully-managed and can continuously capture streaming data with minimal latency
can transport data into data lakes
dynamically partition data based on pre-defined categories to improve query performance
We have identified Amazon Kinesis Data Firehose to be the primary solution for the data delivery stream.
2. AWS tools and resources
Streaming data processing requires two layers: a storage layer and a processing layer.
The storage layer needs to support record ordering and strong consistency to enable fast, inexpensive, and replayable reads and writes of large streams of data. The processing layer is responsible for consuming data from the storage layer, running computations on that data, and then notifying the storage layer to delete data that is no longer needed. [1]
Amazon Kinesisis a platform for streaming data on AWS, offering powerful services to make it easy to load and analyze streaming data. Amazon Kinesis Data Streams can continuously capture and store terabytes of data to power real-time data analysis. Amazon Kinesis Data Firehose can capture and automatically load streaming data into Amazon S3 and Amazon Redshift.
In this use case, we will be using a variety of AWS tools and resources including:
An EC2 instance to generate stimulated clickstream data
An Amazon Kinesis Data Streams to capture real-time clickstream data from EC2
An Amazon Kinesis Data Firehose to deliver streaming data to S3 bucket
An Amazon S3 bucket to persist the streaming data
3. Process & Architecture
As the data engineering team, we are responsible to build a scalable and durable streaming data delivery pipeline for the clickstream data use case.
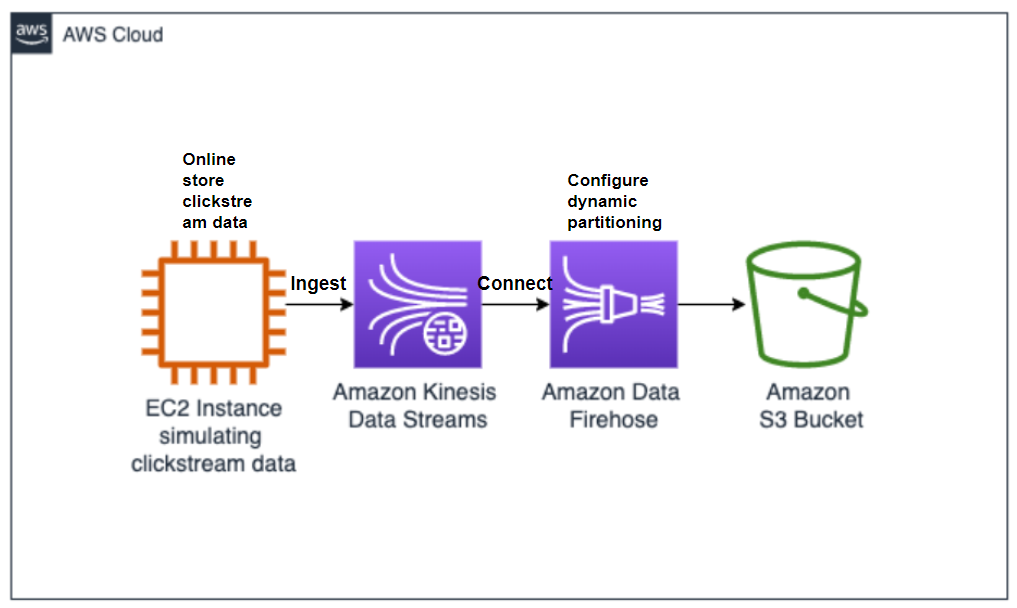
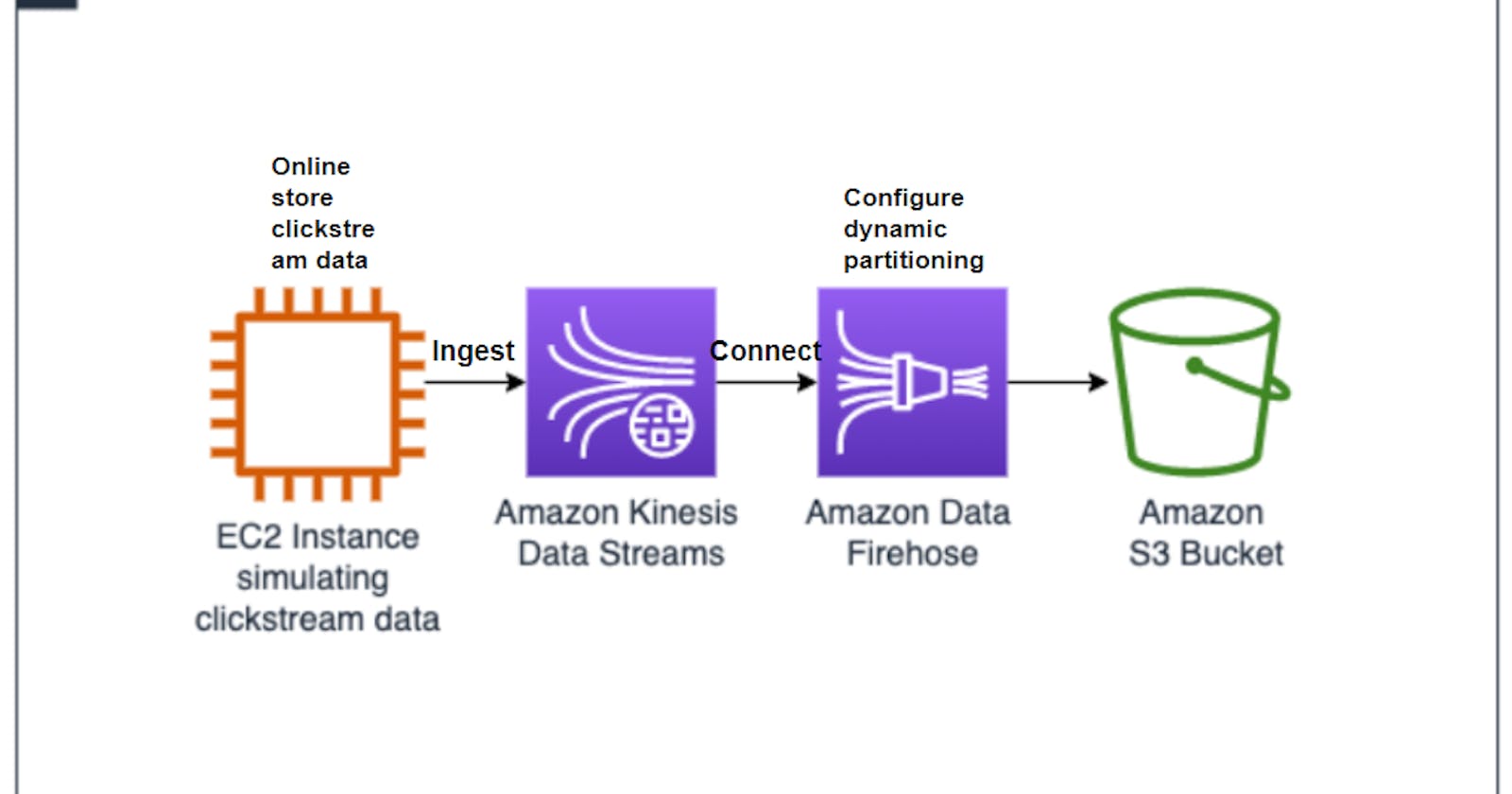
We will first setup a Kinesis Data Streams to ingest the clickstream data generated by an EC2 instance. We will then create and configure a Kinesis Data Firehose delivery stream to connect to a Kinesis Data Stream. On the Kinesis Data Firehose, we will enable dynamic partitioning based on product categories (home products, food, etc.) and finally, we will configure destination settings for the Amazon S3 bucket.
4. Step-by-Step configuration & walkthrough
4.1 Stimulate clickstream data using Amazon EC2
- In the
Session Manager, stimulate a series of clickstream data on an EC2 instance that intimate real-world scenarios: streaming data coming from different devices for different product categories.
🔑 In the command shell, type in:
python3 clickstream_generator_items.py KinesisDataStreamName 1 1
💡Replace <KinesisDataStreamName> with targeted Data Stream Name in real-world cases.
- We will then see the EC2 generate clickstream data from all product categories continuously:

4.2 Create a Kinesis Firehose delivery stream
With Kinesis Data Firehose, you are free from writing applications or managing resources and are able to quickly implement the ELT (Extract, Load, Transform) process in the GUI (Graphical User Interface).

- Go to
Amazon Kinesis, selectDelivery streamsfrom the left panel, and selectCreate delivery stream.

- In the configuration stage, select
Amazon Kinesis Data Streamsas the data source andAmazon S3as the output destination. ForAmazon Kinesis Data Streams, choose the data stream for the clickstream data.

- The
Transformsection is optional. You many transform source records using an Amazon Lambda function or convert the record format. If not applicable, leave all to default settings.

In
Destination settings, choose the designated S3 bucket and enableDynamic partitioning. WithDynamic partitioning, output data will be partitioned into defined categories and be automatically loaded into Amazon S3 with minimal effort and high efficiency.You may partition the source data with
inline parsingorAWS Lambdafunction. In this particular case, we will useinline parsing.


- By using
Inline parsingmethod, we will have to specify key names and JQ expressions to be used dynamic partitioning keys. Looking at the streaming data coming from the online store, we choose to partition incoming data by two partitions:pagewhich refers to which webpage does the event happen, such as food, home products, electronics, etc.; andeventwhich refers to what exact event happens, such as review items, like items, etc..

- For
dynamic partitioning, we must specify the S3 bucket prefix following certain formats since the source data will be partitioned and going to different S3 buckets. You can also specify the S3 bucket error output prefix. This S3 bucket will store all source data that is not able to deliver to the specific S3 destination.
🔑 S3 bucket prefix: !{partitionkeyFromQuery: keyID}
💡In this case, the S3 bucket prefix is set to:
page= !{partitionkeyFromQuery: page}/event= !{partitionkeyFromQuery: event}/

- Click on
Buffer hints, compression and encrptionand choose the optimalbuffer sizeandbuffer interval. Kinesis Data Firehose buffers incoming data before delivering them to the S3 bucket. There is always a trade-offs betweenbuffer sizeandlatency. A recommendedbuffer sizeof128wheredynamic partitioningis enabled is set as default. Thebuffer intervalranges from 60 seconds to 900 seconds. In this use case, we will only use the minimal values.

- Lastly, we will set up the
IAMrole for data stream delivery permission. In this case, we will choose existing role asFirehoseRole.

- Click on
Create delivery streamafter all attributes have been configured.

- It may take 5–10 minutes for the
Kinesis Data Firehoseto create the pipeline. Once the status is changed toactive, we will proceed to S3 buckets to view the results.

4.3 Query results in Amazon S3
- While the
Amazon Kinesis Firehosecontinues delivering data toAmazon S3bucket, we can go to S3 and see that the buckets have been created by page category and event category.

Choose any
pageto view the results and perform some queries. In this case, we choose ‘books’ webpage, and ‘clicked_review’ event.Click on the objects at the left box, click on
Actions, and query data usingAmazon S3 Select. WithAmazon S3 Select, you can use simple SQL statements to filter the contents of an Amazon S3 object stored in CSV, JSON, or Apache Parquet format and retrieve just the subset of data that you need. [2]

- We will use JSON format for both input and output and perform a simple select statement. Remember to only limit the results to 5 records for testing purpose.


- We can now see the 5 records queried by S3 select and the output in the JSON format.

5. Conclusion
In this walkthrough, we have:
created a Amazon Kinesis Firehose that connects to Kinesis Data Stream
configured dynamic partitioning on Amazon Kinesis Firehose delivery stream
delivered data to Amazon S3 and verified the result
This use case mainly focuses on the data delivery stream within the whole streaming data pipeline. As a fully-managed ELT service backboned by AWS, we are able to reliably captures, transforms, and delivers streaming data to data lakes, data stores, and analytics services for future in-depth analysis.
Reference and further readings:
[1] What is streaming data? https://aws.amazon.com/streaming-data/#:~:text=Streaming data includes a wide,devices or instrumentation in data
[2] Filtering and retrieving data using Amazon S3 Select. https://docs.aws.amazon.com/AmazonS3/latest/userguide/selecting-content-from-objects.html