Building Streaming Data Analytics Pipeline using Amazon Kinesis Data Streams (with Apache Flink and Zeppelin notebook)


👉🏻 This walkthrough is to stimulate a real world use case of building a streaming data analytics solutions on AWS for an e-Commerce platform. With Amazon EC2 generated clickstream data, we will be building streaming analytics pipeline in Kinesis Data Analytics Studio and analyzing streaming data interactively using Apache Zeppelin notebooks.
Streaming data is data that is generated continuously by thousands of data sources, such as log files generated by customers using your mobile or web applications, ecommerce purchases, in-game player activity, information from social networks, etc.. [1]
By processing streaming data, companies are able to perform prompt actions based on real-time activities, apply machine learning algorithms for events recommendation, or extract deeper insights from the data.
In the following use case, we will be stimulating web clickstream events for an online shopping platform and using various AWS resources to build streaming data analytics solutions.
1. Use Case Scenario: YCorp. e-commerce platform
Ycorpis an online shopping platform that sells consumer goods such as books, food, apparel, electronics and home products. Ycorp wants to analyze the web clickstream data from e-commerce store in real time and analyze top sales by category from online customers with minimum latency.
As the data engineering teamof Ycorp, we are targeting to build a streaming data analytics solution on AWS to capture the clickstream data with sub-second latencies and respond to events in real time. Besides, we will also be working on enriching the data with catalog data.
We aim to find the solution that can:
be fully-managed and can continuously capture streaming data with minimal latency
build real-time analytics pipeline to ingest, enrich and analyze the clickstream data
visualize data analytics output
We have identified Amazon Kinesis Data Streams with its Apache Flink and Apache Zeppelin notebooks to be the primary solution for the data analytics stream.
2. AWS tools and resources
Amazon Kinesisis a platform for streaming data on AWS, offering powerful services to make it easy to load and analyze streaming data. Amazon Kinesis Data Streams can continuously capture and store terabytes of data to power real-time data analysis. It can easily stream data at any scale and feed data to other AWS services, open source framework and custom applications. [2]
In this use case, we will be using a variety of AWS tools and resources including:
An EC2 instance to generate stimulated clickstream data
An Amazon Kinesis Data Streams to ingest data
A Kinesis Data Analytics Studio with Apache Flink to develop the analytics workload and Apache Zeppelin notebook to visualize the data
An Amazon S3 bucket where catalog data is stored
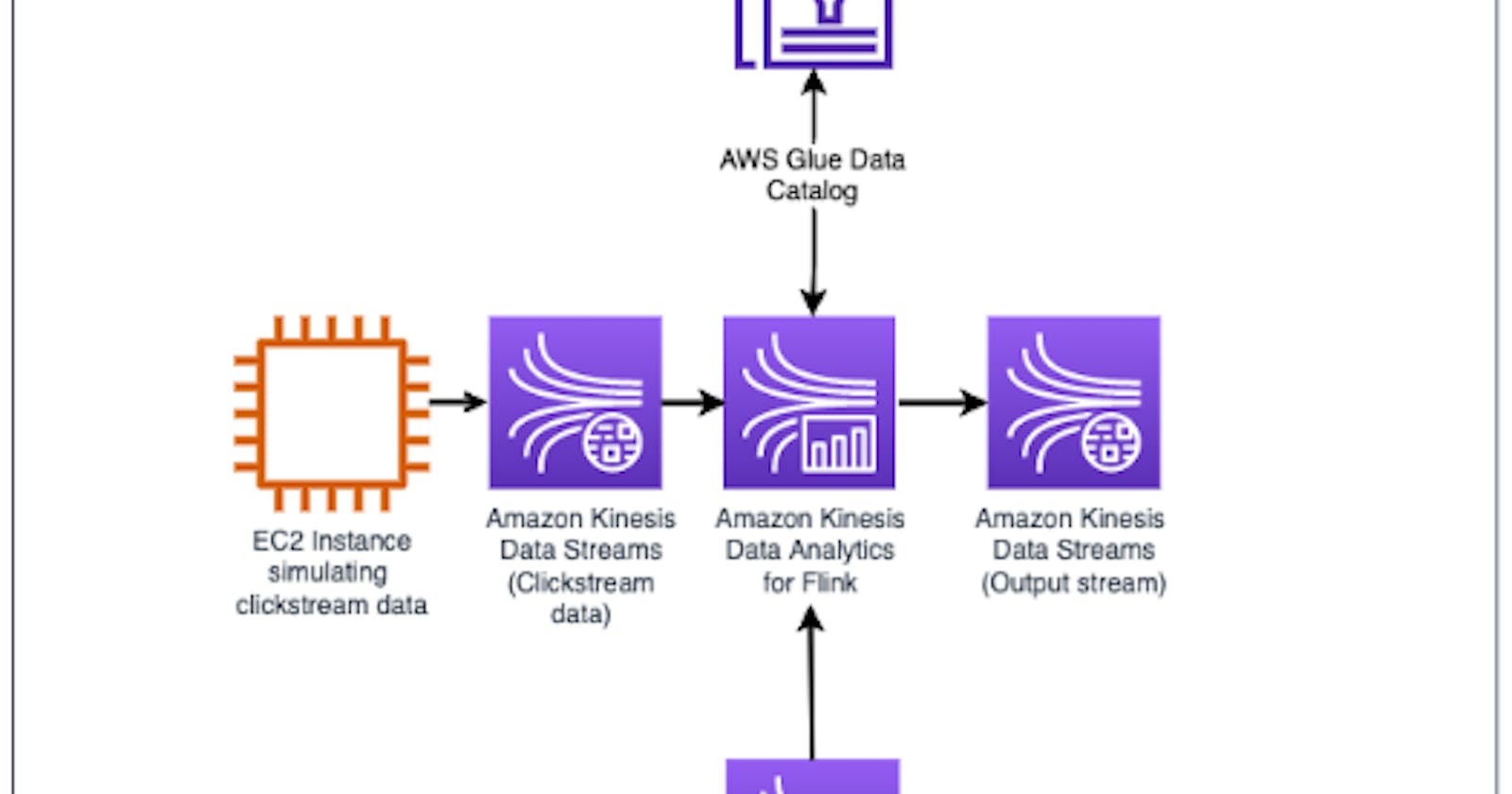
3. Process & Architecture
As the data engineering team, we are responsible to build a scalable and near real-time streaming data analytics pipeline for the web clickstream data use case.

We will first setup a Kinesis Data Streams to ingest the clickstream data generated by an EC2 instance. We will then ingest the clickstream data (from EC2) and enrich the dataset with Catalog data from Amazon S3 using Apache Flink and Zeppelin notebook. We will visualize the data results to determine top Sales within a time window of 10-second and finally, we will output the data to Kinesis Data Streams for downstream processing.
4. Step-by-Step configuration & walkthrough
4.1 Stimulate clickstream data using Amazon EC2
- In the
Session Manager, stimulate a series of clickstream data on an EC2 instance that intimate real-world scenarios: streaming data coming from different devices for different product categories.
🔑 In the command shell, type in:
python3 clickstream_generator_items.py KinesisDataStreamName 1 1
💡Replace <KinesisDataStreamName> with targeted Data Stream Name in real-world cases.
We will then see the EC2 generate clickstream data from all product categories continuously:

4.2 Set up Zeppelin notebook
Apache Zeppelin notebook is an open source, web-based notebook that enables data-driven, interactive data analytics and collaborative documents with SQL, Scala, Python, R and more languages. [3]
In this use case, we will setup a Kinesis Data Analytics Studio notebook powered by Apache Zeppelin to interactively query data streams in real time. We will use FlinkSQL queries in the Studio notebook to query streaming data. We will be able to view the results while the data streams are updating in the real time. [4]
Kinesis Data Analytics Studio notebook uses notebooks powered by Apache Zeppelin and Apache Flink as the stream processing engine.
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Apache Flink has been designed to run in all common cluster environments and can perform computations at in-memory speed.
- Go to
Amazon Kinesis, selectAnalytics application, then selectStreaming applications. Select theStudiotab, and click onCreate Studio notebook. In this use case, we will be running a pre-configuredStudio notebookfor explanatory purpose.

- There are 3 steps in running
Studio notebook. After initiating the notebook, it will take approximately a few minutes for the notebook to get toRunningstate. Once running, we will be able to useApache Zeppelinto analyze the streaming data. Click onRunto initiate the notebook.

- After the notebook is
Running, click onOpen in Apache Zeppelin.

- After opening
Zeppelin notebooks, all existing notes are listed on the left side. We will create a notebook to analyze the data streams interactively.

4.3 Analytics development with Apache Zeppelin notebook
In the Apache Zeppelin notebook environment, we will be ingesting two data sources to the Studio:
Web clickstream data (generated by EC2 clickstream generator)
Catalog data stored in Amazon S3
4.3.1 Clickstream Data and Catalog Data Ingestion
- We will create an in-memory table for the web clickstream data.
👉🏻 Creates the in-memory table clickstream_events and defines the table with its element.
💡Apache Flink will use this statement to define the metadata for records coming into a data stream using a Kinesis connector.
%flink.ssql
DROP TABLE IF EXISTS clickstream_events;
CREATE TABLE clickstream_events ( -- Create in-memory table and define table elements
event_id STRING,
event STRING,
user_id STRING,
item_id STRING,
item_quantity BIGINT,
event_time TIMESTAMP(3),
os STRING,
page STRING,
url STRING
)
WITH (
'connector' = 'kinesis',
'stream' = 'YOUR_ClickstreamDataStream', -- Replace with your clickstream data path
'aws.region' = 'YOUR_Region', -- Replace with your aws region
'scan.stream.initpos' = 'LATEST',
'format' = 'json'
);
- To ensure we have successfully created the
clickstream_eventstable, we will perform aSelect *statement to pull the data and see the table results.
%flink.ssql(type=update)
SELECT * FROM clickstream_events;

- We will then create an in-memory table for the item catalog in Amazon S3.
👉🏻 There will be a three-step process for create the Catalog Data
1. Create an in-memory table to read catalog data from S3: catalog_items_s3
2. Create an in-memory table for Kinesis Data Streams to ingest catalog data: catalog_items_stream
3. Insert catalog data to catalog_items_stream

%flink.ssql(type=update)
DROP TABLE IF EXISTS catalog_items_s3; -- Create an in-memory table to read catalog data from S3 bucket
CREATE TABLE catalog_items_s3(
item_id STRING,
item_name STRING,
item_price STRING,
page STRING
)
WITH (
'connector' = 'filesystem',
'path' = 's3a://YOUR_DataBucketName/input/', -- Replace with your bucket name
'format' = 'json'
);
%flink.ssql(type=update)
DROP TABLE IF EXISTS catalog_items_stream;
CREATE TABLE catalog_items_stream ( -- Create an in-memory table for Kinesis Data Streams to ingest catalog data
item_id STRING, -- Note that it has the same elements with catalog_items_s3
item_name STRING,
item_price STRING,
page STRING
)
WITH (
'connector' = 'kinesis',
'stream' = 'YOUR_ItemDataStream', -- Replace with your clickstream data path
'aws.region' = 'YOUR_Region', -- Replace with your aws region
'scan.stream.initpos' = 'TRIM_HORIZON',
'format' = 'json'
);
%flink.ssql(type=update)
INSERT INTO catalog_items_stream
SELECT item_id,
item_name,
item_price,
page
FROM catalog_items_s3; -- Insert elements from S3 in-memory table
- To ensure we have successfully created the
catalog_items_streamtable, we will perform aSelect *statement to pull the data and see the table results.
%flink.ssql(type=update)
SELECT * FROM catalog_items_stream;

- Once we have the clickstreams data and catalog data, we can enrich the dataset by performing a
JOINstatement.
%flink.ssql(type=update)
SELECT *
from clickstream_events
inner join catalog_items_stream
on clickstream_events.item_id = catalog_items_stream.item_id;
4.3.2 Data Visualization
- We will utilize Zeppelin notebooks’ visualization feature to display and determine the Sales per category in the last 10 seconds. We will use
TUMBLE PROCTIMEstatement to create a mini-batch of data in a 10-second tumbling window on top of a Sum ofpurchased_items.
%flink.ssql(type=update)
SELECT
TUMBLE_START(PROCTIME(), INTERVAL '10' seconds) as start_window,
TUMBLE_END(PROCTIME(), INTERVAL '10' seconds) as end_window,
clickstream_events.page,
SUM(CAST(item_price as FLOAT) * item_quantity) AS SALES
from clickstream_events
inner join catalog_items_stream
on clickstream_events.item_id = catalog_items_stream.item_id
WHERE (event= 'purchased_item')
GROUP BY TUMBLE(PROCTIME(), INTERVAL '10' seconds ),clickstream_events.page, item_price;

4.3.2 Data output to Kinesis Data Stream
- The last step of data streams analytics would be to output the data to a
Kinesis Data Streamfor downstream processing. We will create an in-memory table to hold the output data.
%flink.ssql(type=update)
DROP TABLE IF EXISTS sink_table;
CREATE TABLE sink_table ( -- Create an in-memory table to store output data for downstream processing
event_id STRING,
event STRING,
user_id STRING,
item_id STRING,
item_quantity BIGINT,
event_time TIMESTAMP(3),
os STRING,
page STRING,
url STRING,
item_name STRING,
item_price STRING
)
WITH (
'connector' = 'kinesis',
'stream' = 'YOUR_OutputDataStream', -- Replace with your clickstream data path
'aws.region' = 'YOUR_Region', -- Replace with your aws region
'scan.stream.initpos' = 'LATEST',
'sink.producer.aggregation-enabled' ='false',
'format' = 'json'
);
%flink.ssql(type=update)
INSERT INTO sink_table
SELECT
event_id,
event,
user_id,
catalog_items_stream.item_id,
item_quantity,
event_time,
os,
catalog_items_stream.page,
url,
item_name,
item_price
from clickstream_events
inner join catalog_items_stream
on clickstream_events.item_id = catalog_items_stream.item_id;
5. Conclusion
In this walkthrough, we have:
created a real-time streaming analytics pipeline in Amazon Kinesis Data Analytics Studio
used Apache Flink and Apache Zeppelin notebooks to ingest, enrich and visualize the streaming data
output the data to Kinesis Data Streams for downstream processing
This use case mainly focuses on the data ingestion and analytics stream within the whole streaming data pipeline. We have utilized AWS Kinesis Data Streams to source clickstream data and enrich the dataset with Catalog data, and interactively visualized the data in real-time.
p.s. If you are interested in learning data delivery stream within the whole pipeline, you may read this article 👉🏻 Building Streaming Data Delivery Pipeline on AWS using Amazon Kinesis solution.
Reference and further readings:
[1] What is streaming data? https://aws.amazon.com/streaming-data/#:~:text=Streaming
[2] Amazon Kinesis Data Streams. https://aws.amazon.com/kinesis/data-streams/
[3] Zeppelin notebook. https://zeppelin.apache.org/
[4] What Is Amazon Kinesis Data Analytics for Apache Flink? https://docs.aws.amazon.com/kinesisanalytics/latest/java/what-is.html